-
<연습 문제1>

--A. JOB이 JOB으로 정렬되어 있고, SAL이 DESC되어있고, GRADE도 DESC되어있다. --EMP 테이블과 SALGRADE 테이블이 JOIN되어 있다. -- SELECT E.*, G.GRADE FROM EMP E JOIN SALGRADE G ON E.SAL >= G.LOSAL AND E.SAL <= G.HISAL WHERE G.GRADE IN (1,2,3,4,5) ORDER BY G.GRADE DESC, E.SAL DESC ;> where은 안써도 되는 것 같아 - 어차피 전부 다 해당해야하는 거니까. 삭제해도 문제 없는 거 같아.
select e.*, s.grade from emp e join salgrade s on e.sal between s.losal and s.hisal order by s.grade desc, e.sal desc ;> join문 사용했고, on 다음에 해당되는 column 그리고 between썼어 > 범위가 전체니까
SELECT E.*, S.GRADE FROM EMP E, SALGRADE S WHERE E.SAL BETWEEN S.LOSAL AND S.HISAL ORDER BY GRADE DESC;> join문 사용 안해서 where로 들어왔네 나머지는 같다.
<연습 문제2>
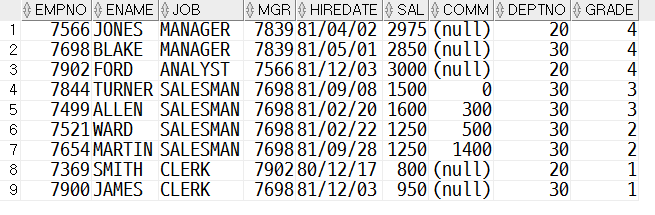
--B. JOB이 정렬되어있고, DEPTNO가 20, 30인 직원들만 출력, GRADE가 DESC되어있다. SELECT E.*, G.GRADE FROM EMP E JOIN SALGRADE G ON E.SAL >= G.LOSAL AND E.SAL <= G.HISAL WHERE E.DEPTNO IN (20, 30) ORDER BY G.GRADE DESC ;>
SELECT E.*, S.GRADE FROM EMP E, SALGRADE S WHERE E.SAL BETWEEN S.LOSAL AND S.HISAL AND DEPTNO <> 10 ORDER BY S.GRADE DESC;> deptno가 10, 20, 30밖에 존재하지 않다는 걸 알아서, '10이 아닌'으로 제한조건을 줄였고, where 절의 연장으로 and를 사용했다. 나는 뭔가 and를 쓰고 and를 또 쓰는 게 어색해서,,, 이것도 된다는 것을 잘 알아둬야 할 것 같다. 앞의 and는 between에 걸리는 거고, 뒤에 and는 where에 걸리는 건데, 여기서는 자바와 다르게 캡슐화를 안시키니까 헷갈리면 안된다.
SELECT E.*, S.GRADE FROM EMP E JOIN SALGRADE S ON E.SAL BETWEEN S.losal and S.hisal WHERE E.DEPTNO IN (20,30) ORDER BY S.GRADE DESC , E.SAL DESC;> 나랑 큰 틀은 비슷한데, between A and B로 더 간단하게 만든 부분을 참고하자.
<연습 문제3>

조건 :
-
DEPTNO가 20,30인 부서 사람들의 평균연봉을 계산하도록 한다.
-
연봉 계산은 SAL*12+COMM
-
순서는 평균연봉이 내림차순으로 정렬한다
--GRADE와 AVG(SAL)이 나타나 있다. GRADE DESC --평균연봉 SAL*12+COMM이니까 COMM이 NULL인 사람 0으로 계산하게끔 만들고 --각 GRADE의 사람들끼리 묶어서 평균 연봉을 계샌해야해. SELECT G.GRADE, AVG(SAL*12+NVL2(COMM, COMM, 0)) 평균연봉 FROM SALGRADE G JOIN EMP E ON SAL >= G.LOSAL AND SAL <= G.HISAL WHERE E.DEPTNO IN (20, 30) group by G.GRADE --요게 KEY였네. 프로그램이 알아서 해줬음 ORDER BY 평균연봉 DESC ;> group by 에 대한 개념이 확실히 잘 안잡혀있는 게 느껴진다.
왜 쓰는지? - GRADE에 따라서 정리가 되어 있잖아.
어떻게 쓰는지? - 묶고싶을 때 쓰는 거겠지?, 여기선 grade로 묶었지만, 부서별로 묶고싶을 땐 deptno으로 묶는다거나 할 수 있겠지.
어떤 원리로 적용이 되는지? - 아마 select에 존재하는 column이어야하지 않을까?
이러한 질문들에 답을 할 수 있을 정도로 알아봐야지.
SELECT S.GRADE, AVG(NVL2(COMM, E.SAL*12+COMM, E.SAL*12)) 평균연봉 FROM EMP E, SALGRADE S WHERE E.SAL BETWEEN S.LOSAL AND S.HISAL AND DEPTNO <> 10 GROUP BY S.GRADE ORDER BY S.GRADE DESC> 앞선 모양은 비슷한데, NVL2를 쓰는 방식이 좀 달랐어. 차이점들 참고해
// C문제에 D조건 추가한 것임. SELECT S.GRADE, AVG((12*E.SAL)+NVL(COMM,0)) AS 평균연봉 FROM EMP E JOIN SALGRADE S ON E.SAL BETWEEN LOSAL AND HISAL WHERE E.DEPTNO IN (20,30) GROUP BY S.GRADE ORDER BY 평균연봉 DESC;> NVL2가 아니라 그냥 NVL을 썼어
<연습 문제4>

SELECT E.*,D.DNAME,D.LOC,S.GRADE FROM EMP E, DEPT D, SALGRADE S WHERE E.SAL BETWEEN LOSAL AND HISAL AND E.DEPTNO=D.DEPTNO ORDER BY S.GRADE;> grade도 나오고 location도 나오니까, 테이블 3개가 연결되어야 했던거야
3개니까 join을 쓰기엔 애매한 상황인 것 같아 나는 그냥 3개를 연달아 from에 적었어 그리고 where에 이 3개를 연결할 수 있는 조건들을 나열한거지
select e.*, d.loc, g.grade from emp e, dept d, salgrade g where e.deptno = d.deptno and e.sal between g.losal and g.hisal ;> 같은 맥락이었네
SELECT E.*, D.DNAME, D.LOC, S.GRADE FROM EMP E, DEPT D, SALGRADE S WHERE E.DEPTNO = D.DEPTNO AND E.SAL BETWEEN S.LOSAL AND S.HISAL ORDER BY GRADE;> 다른 답변들을 보니까 여기선 아마 join을 쓰면 안되는 게 맞는 것 같아.
<연습 문제5>
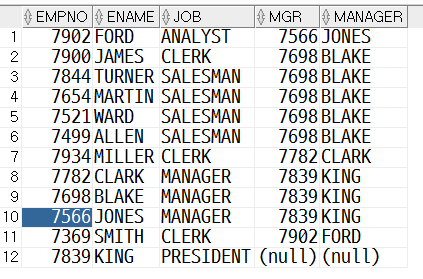
select e.empno, e.ename, e.job, e.mgr, m.ename manager from emp e join emp m on e.mgr = m.empno ;> 이 연습 문제가 좀 어려운 부분은, equi join이고, 자칫 잘못하면 진짜 뜬금없는 결과가 출력된다는 거야
그래서 가상의 emp 테이블을 생각하면서 해야해
지금 m.ename에 매니저 이름을 넣어야 한다고 생각을 먼저 하고,
on 문에서 m.empno(ename 의 unique한 값이니)가 e.mgr로 대입시킨다고 생각하면 수월해지지.
반복하면서 익숙해지자.
SELECT E.EMPNO, E.ENAME, E.JOB, E.MGR, M.ENAME MANAGER FROM EMP E LEFT OUTER JOIN EMP M ON E.MGR = M.EMPNO;> left outer join을 썼는데, 나는 아직 여기에 익숙치가 않아서. 직접 해보자
SELECT E.EMPNO, E.ENAME, E.JOB, E.MGR, (SELECT M.ENAME FROM EMP M WHERE E.MGR=M.EMPNO) MANAGER FROM EMP E ORDER BY MGR;> sub query를 select문에 넣어놨어. 전혀 생각지 못했네.
이 방법으로 하면 헷갈리는 게 훨씬 줄어드는 것 같아.
자바같이 캡슐화를 시켜서 정리가 깔끔하잖아.
<연습 문제6>
MARTIN의 월급보다 많으면서 ALLEN과 같은 부서이거나 20번부서인 사람을 찾아주세요
select * from emp where sal > (select sal from emp where ename = 'MARTIN' ) and deptno in (20, (select deptno from emp where ename = 'ALLEN' ) ) ;> 그리 어렵지 않았는데, 대소문자 구별이 문자에서는 필요하다는 것을 몰라서 처음에 적잖이 당황했어
소문자로 이름을 적었다가 결과값이 안나와서 당황했고, 대문자로 바꾸니까 잘 되더라.
SELECT * FROM EMP WHERE SAL > (SELECT SAL FROM EMP WHERE ENAME = 'MARTIN') AND DEPTNO IN (20, (SELECT DEPTNO FROM EMP WHERE ENAME = 'ALLEN'));> 똑같은 듯 해
SELECT * FROM EMP WHERE SAL >= ( SELECT SAL FROM EMP WHERE ENAME='MARTIN' ) AND (DEPTNO = '20' OR DEPTNO = (SELECT DEPTNO FROM EMP WHERE ENAME='ALLEN'));> in 을 쓰지 않아서 eptno = 를 2 번 썼어야 했네.
<연습 문제7>
‘RESEARCH’부서의 사원 이름과 매니저 이름을 나타내시오.
select e.ename, m.ename manager from emp e, emp m where m.empno = e.mgr and e.deptno = (select deptno from dept where dname = 'RESEARCH') ;> 그리 어렵지 않았다
SELECT E1.ENAME, E2.ENAME FROM EMP E1, EMP E2 WHERE E1.MGR = E2.EMPNO AND E1.DEPTNO = (SELECT DEPTNO FROM DEPT WHERE DNAME = 'RESEARCH');> 똑같은 답인듯?
SELECT E.ENAME, (SELECT M.ENAME FROM EMP M WHERE E.MGR=M.EMPNO) MANAGER FROM EMP E WHERE E.DEPTNO = ( SELECT D.DEPTNO FROM DEPT D WHERE D.DNAME='RESEARCH');> 여기도 헷갈리는 게 줄어들 수 있게끔 sub query를 select에 가져왔어
좋은 참고 자료!
<연습 문제8>
‘RESEARCH’부서의 사원 중 전사원의 평균월급보다 많은 사원의 사원번호, 이름, 업무(JOB), 월급, 부서(DEPT)명, 부서위치를 나타내시오.
select e.empno, e.ename, e.job, e.sal, d.dname, d.loc from emp e join dept d using(deptno) where e.sal > (select avg(sal) from emp ) and deptno = (select deptno --후의 deptno도 테이블명 다 지워야 하는듯? from dept where dname = 'RESEARCH') ;> 맞는데 길이를 줄일 수 있는 방법이 있지
SELECT E.EMPNO, E.ENAME, E.JOB, E.SAL, D.DNAME, D.LOC FROM EMP E, DEPT D WHERE E.DEPTNO = D.DEPTNO AND E.DEPTNO = (SELECT DEPTNO FROM DEPT WHERE DNAME = 'RESEARCH') AND E.SAL > (SELECT AVG(SAL) FROM EMP);> 나랑 똑같은 답을 했네, 나는 using을 썼고, 여긴 where로 묶어놨고
SELECT E.EMPNO, E.ENAME, E.JOB, E.SAL, D.DNAME, D.LOC FROM EMP E JOIN DEPT D USING(DEPTNO) WHERE E.SAL > (SELECT AVG(SAL) FROM EMP) AND D.DNAME='RESEARCH';> 훨씬 간단히 한거같아. 나는 sub query를 하나 더 썼는데, 여기는 그냥 d.dname = 'research'로 끝냈어
<연습 문제9>
각 부서별로 가장 높은 월급을 받는 사원을 나타내시오. MAX(SAL) 사용
SELECT E.* FROM EMP E, (SELECT DEPTNO, MAX(SAL) SAL FROM EMP GROUP BY DEPTNO) EX WHERE E.DEPTNO = EX.DEPTNO AND E.SAL = EX.SAL;> '각 부서별로'라는 말이 들어갔으니까 group by deptno가 필수로 들어야가지! 그 위치를 정하는 건 자기 취향인 듯 해!
여기서는 from에 넣어서 sub query 를 하나의 테이블로 만들었네, 그래서 where로 그 테이블을 묶고
e.sal = ex.sal만 하면 다른 그룹에서의 최댓값이 또 다른 그룹에서의 최댓값이 아닌 경우 출력되는 것을 막기 위해
e.deptno = ex.deptno를 사용했다고 볼 수 있겠네
SELECT DEPTNO, ENAME, SAL MAX월급 FROM EMP WHERE ( DEPTNO, SAL ) IN (SELECT DEPTNO, MAX(SAL) FROM EMP GROUP BY DEPTNO);> 여기도 group by deptno 를 썼는데 위치가 좀 독특하네
그리고 다중 서브쿼리를 써서 바로 전에 나타냈던 e.deptno = ex.deptno를 안써도 되게끔 했네. 하나로 묶어놨으니까 진즉에!
나는 이 방법이 더 좋은 거 같아.
deptno과 sal를 묶어놓고 결국 max(sal)이 출력되게끔 한거잖아?
근데 여기에 in을 써야하는 건가? 나한테 in은 뭔가 '둘 중에 하나' 라는 느낌이라 확 와닿진 않네.
<연습 문제10>
각 업무별 가장 낮은 월급을 받는 사원을 나타내시오. MIN(SAL) 사용SELECT E.* FROM EMP E, (SELECT JOB, MIN(SAL) SAL FROM EMP GROUP BY JOB) EX WHERE E.JOB = EX.JOB AND E.SAL = EX.SAL;> 똑같은 답변인데, max가 min으로 바뀐거지!
select deptno, ename, sal from emp where (deptno, sal) in (select deptno, min(sal) from emp group by deptno) ;> 위에 내가 마음에 든다는 방식으로 다시 써봤어! 이걸 것 같은데?
---다중 서브 쿼리--- SELECT EMPNO, ENAME, SAL DEPTNO FROM EMP WHERE (DEPTNO, SAL, ENAME) IN ( SELECT DEPTNO, SAL, ENAME FROM EMP WHERE DEPTNO = 30 ) ;> 이걸 이제 쓸 수 있으니까, 앞서 이야기 했듯이,
그룹으로 묶였을 때 특히! 예상치 못한 결과를 피할 수 있을 것 같아! 하나로 묶이잖아 !
---스칼라 서브쿼리--- --SELECT문에서 쓰이는 단일행 서브쿼리를 의미 SELECT ENAME, DEPTNO,SAL, (SELECT TRUNC(AVG(SAL)) FROM EMP WHERE DEPTNO = E.DEPTNO) AS AVGDEPTSAL FROM EMP E ;> trunc가 나머지 값 버리는 거였나,,?
select 문에 쓰이는 단일행 서브 쿼리를 스칼라 서브 쿼리라고 하는구나,,, 알아둬,,,,
--부서위치가 NEW YORK인 경우에 본사로, 그 외부서는 분점으로 리턴하는 쿼리를 CASE문을 통해 실행 SELECT EMPNO, ENAME, CASE -- 케이스 설정, WHEN DEPTNO = (SELECT DEPTNO -- 분류가 되는 기준: DEPTNO니까 DEPTNO를 기준으로 FROM DEPT -- DEPTNO와 LOC가 둘다 들어있는 테이블 WHERE LOC = 'NEW YORK') --'VALUE'는 ' '를 해야지, THEN '본사' -- 뉴욕일 때 본사로 하고 나머지 분점으로 설정하는 게 제일 효율적, 반대는 WHEN을 많이 써야해 ELSE '분점' -- 나머지 다 퉁치기, SWITCH / DEFAULT 느낌 END --CASE의 범위가 끝나는 지점 필수!!! AS 소속 --여길 먼저 설정해놓고 -- 'SCHEMA'는 ' '필요없구; FROM EMP E ORDER BY 소속 DESC -- PRMIARY KEY ASC 생략되어있어 ;> select 부분에 case를 넣어서 소속이 나타나게끔 하는 구문.
딱 봤을 때 이해 안되는 느낌은 아닌데, 어색한 느낌
적재 적소에 쓰는 것이 중요한데, 원하고자 하는 출력문을 생각을 하고 이러한 transaction을 바로 상상할 수 있어야지
case문 안에 또 sub query가 있어서 복잡해 보이지만 풀어 해석해 보면 별 거 아니야
---상호연관 서브쿼리--- SELECT E.ENAME, E.JOB, D.DNAME FROM EMP E JOIN DEPT D USING (DEPTNO) --DEPTNO만 테이블명 지우면 돼! 나머지는 그대로 해도 ㄱㅊ ;> 요건 알고 있던 거 아닌가??
-- 94 하단 -- JOIN SELECT E.NAME, E.JOB FROM EMP E JOIN DEPT D USING (DEPTNO) WHERE D.DANE = 'SALES' ;> using 쓰고 where 쓰는 거
원래 on 다음에도 조건 걸 거 있음 where 쓰는 데, using이 on 역할 대신 한거라 바로 where 나오네
-- 94 -- 상관 서브쿼리 SELECT ENAME, JOB FROM EMP E WHERE DEPTNO = (SELECT DEPTNO --여기에 아무거나 들어가도 된다고? 왜? FROM DEPT WHERE DEPTNO = E.DEPTNO --JOIN AND DNAME = 'SALES') ;> 아무거나 들어가도 된다고 왜 필기했지?
-- 급여가 20부서의 평균연봉보다 높은데 20부서 소속이 아닌사람 SELECT B.EMPNO, B.ENAME, B.JOB, B.SAL, B.DEPTNO--B가 MAIN QUERY FROM (SELECT EMPNO FROM EMP WHERE SAL > (SELECT AVG(SAL) FROM EMP WHERE DEPTNO=20 --아까 구한거 ) ) A, EMP B --어 원래 이름 앞에 AS 써도 되는 거 아냐?? WHERE A.EMPNO = B.EMPNO AND B.MGR IS NOT NULL AND B.DEPTNO !=20 ;> 조건 걸 대상이 달라지면 where을 2번 써도 되네
-- 96 하단 order by subquery select empno, ename, deptno, hiredate from emp e order by ( select dname from dept where deptno = e.deptno ) desc ; -- 현재 조회한 column이 아니라 다른 column value로 정렬하고자 할 때 사용> dname으로 정렬을 하고싶은데, 원래였음 select에 dname이 column으로 들어갔어야 했어. 근데 그러기 싫어서 order by에 sub query로 dname을 select한거지, 이럴 땐 where 로 연결고리도 놔줘야해
-- union -- 여러개의 sql문이 결과에 대한 합집합. 중복행을 하나의 행으로 보여준다. select empno, ename, job, sal from emp where job = 'salesman' union all select empno, ename, job, sal from emp where sal > 1300 ;> 그냥 싹다 보이게끔, 결과 두 개를 보여주고 합쳐버린다.
책 초반부 p.4 ~ p.41 정독
-